Updated July 1, 2026. Fable 5 is available again after the June 12–30 export-control suspension — so this comparison is runnable once more. Pro/Max/Team plans include Fable at 50% of weekly limits through July 7. Latest news →
FableGuide › Fable 5 vs GPT-5.5
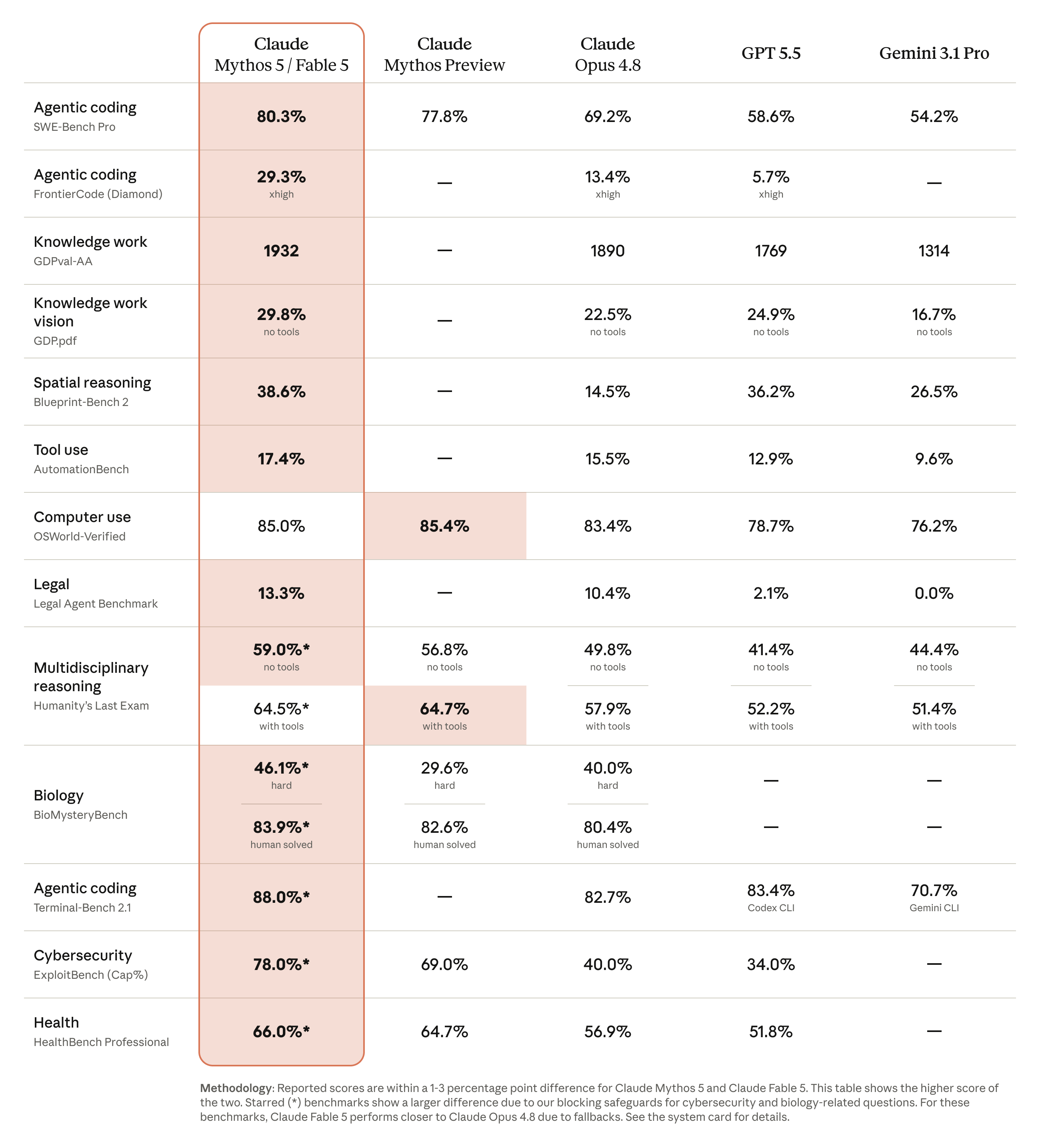
What the evidence shows so far
- Frontier physics research — the most concrete cross-vendor data point, though a single partner's report, not an independent eval. Matthew Pines of Notation Capital, quoted in Anthropic's June 9, 2026 announcement: Fable was "the strongest model on frontier physics research while using a third of the reasoning tokens. In 36 hours it got nearly to where GPT-5.5 landed after four days." One named, dated source — weigh as a partner datapoint, not a benchmark.
- Anthropic's benchmark table — the announcement's comparison chart puts Fable at state-of-the-art on nearly all tested benchmarks against other leading models. Vendor-published — weigh accordingly.
- Hands-on community tests — early side-by-sides on hard coding prompts lean Fable (a hard-prompt comparison and a 6-surprising-uses comparison) — enthusiast-grade, single-author evidence, ranked on our charts. Treat as impressions, not measurement.
{kind=link}
What doesn't exist yet
Independent, methodical cross-vendor evals — LMArena-style rankings with Fable included, third-party SWE-bench runs, cost-normalized agentic comparisons. The June 12–30 suspension froze that work for most of Fable's first month; with the model restored July 1, expect it to resume. The evidence wall adds results as they publish; claims without receipts don't go up, and that cuts in both directions.
The structural differences you can compare today
| Fable 5 | GPT-5.5 | |
|---|---|---|
| Positioning | Highest-capability tier, safeguarded Mythos-class | OpenAI's frontier flagship |
| Sampling controls | None — prompting only | Vendor-specific |
| Reasoning control | Adaptive thinking + 5 effort levels | Vendor-specific |
| Context | 1M tokens, no long-context premium | See OpenAI's current docs |
| Safety architecture | Runtime classifiers + Opus 4.8 fallback, published red-team numbers | Different approach; see OpenAI's system card |
We deliberately don't quote GPT-5.5 specs from memory — vendor docs change. Check OpenAI's current documentation for their side of the table.
Run your own bake-off (an afternoon, ~$20)
- Pick your three hardest real tasks from the last month — not puzzles, your actual work.
- Write each as one complete brief: goal, constraints, what "done" looks like. (This favors no one — both frontier models reward specification.)
- Run each on both models. For Fable use our recommended defaults: adaptive thinking, effort
high. - Score on: did it finish without intervention; correctness; total cost from the usage fields — not tokens, completed-task cost.
- Post-return note: Fable's new safety classifier can false-positive on routine coding and hand a task to Opus 4.8 with a notification — log those runs as data, not noise.
Moral: benchmarks are other people's tasks. The only chart that matters is yours.